In the dynamic landscape of data analysis, SQL (Structured Query Language) stands as a cornerstone, playing a pivotal role in managing and dissecting structured data. Remarkably, as of 2024, more than 225,000 companies are leveraging an SQL server for database management and analysis, highlighting its indispensable role. Put differently, the Microsoft SQL server database serves as the bedrock upon which insightful decision-making is constructed in modern-day business environments, allowing for the seamless handling of structured data.

SQL’s significance is unparalleled compared to its alternatives offering similar functionality, especially when it comes to SQL Pivot. SQL Pivot is a powerful technique for reshaping data within SQL’s extensive capabilities for data manipulation and analysis. This capacity to pivot and restructure data sets SQL apart, enabling businesses to glean meaningful patterns and trends from their data.
As we navigate through the intricacies of SQL, it becomes evident that it is more than just a language for database management; it is a catalyst for informed decision-making. The versatility of SQL and, consequently, SQL Pivot data, lies not only in its ability to handle and organize vast datasets but also in its power to extract actionable insights from these data structures.
This blog post delves into the fundamentals of SQL, unravels the transformative power of pivoting in SQL, dissects the PIVOT function in SQL, and addresses the nuanced challenges of handling big data within this framework, among other things. For that reason, whether you are a seasoned analyst or just beginning your journey in data analysis, we invite you to read along and learn how to harness the full potential of SQL, make the most out of SQL Pivot, and enable yourself to extract actionable insights and make informed decisions in your business endeavors.
Fundamentals of SQL
SQL serves as the cornerstone for managing and retrieving structured data within relational databases. At its core are fundamental commands essential for crafting precise queries. SELECT, the linchpin, allows users to select a query and to identify and retrieve specific data, while FROM specifies which query produces the data source, establishing the foundation for analysis. The WHERE command acts as a filter, refining results based on specified conditions and enhancing the precision of data extraction.

In parallel, mastering SQL syntax rules is akin to grasping the language’s grammar. These rules govern the composition of queries, ensuring syntactical accuracy. They dictate the arrangement of commands, detailing the precise sequence for effective data retrieval. A solid understanding of these syntax rules empowers data analysts to navigate relational databases with finesse and construct intricate queries, unlocking the potential for nuanced and comprehensive data analysis.
Importance of SQL in Data Analysis Workflows
Now that we’ve equipped ourselves with the basics let’s explore the integral role of SQL in data analysis workflows.
SQL serves as the linchpin in these processes, orchestrating data extraction, transformation, and loading (ETL). Imagine SQL as the conductor, seamlessly harmonizing the disparate elements of structured data.

SQL acts as the bridge in data extraction, connecting you to the specific information you need. SQL’s capabilities shine during the transformation phase as it refines and structures data to meet your analysis requirements. Loading, the final step, involves efficiently storing the transformed data for future use.
By recognizing SQL’s pivotal role in these workflows, you gain a deeper appreciation for its contribution to efficient and effective data analysis.
Now that we’re through with explaining the fundamentals of the domain-specific language utilized for programming, designing, and managing data, we can head down to the main subject of this blog post and explain the power of SQL Pivot and how the PIVOT function in SQL works.
The Power of Pivoting in SQL
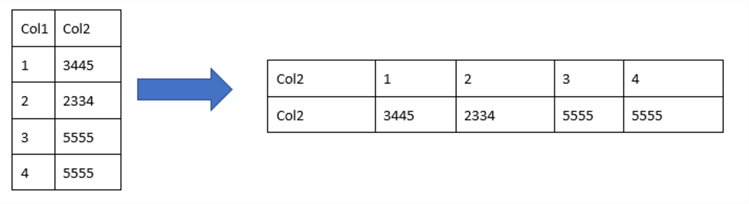
In data analysis, the ability to pivot data using SQL proves to be a transformative technique with far-reaching implications. As pivoting is the process of rotating data from rows to columns or converting row values into multiple columns together, thus offering a dynamic approach to reshaping information, this method not only enhances data readability but also simplifies complex datasets, revealing patterns that might be obscured in the original format.
SQL’s pivotal role in this process is exemplified through its dedicated PIVOT SQL function, a powerful tool enabling users to rotate SQL Pivot data based on specified column values. This function facilitates a more intuitive representation of information, fostering a clearer understanding of relationships within the dataset and the pivoting data.
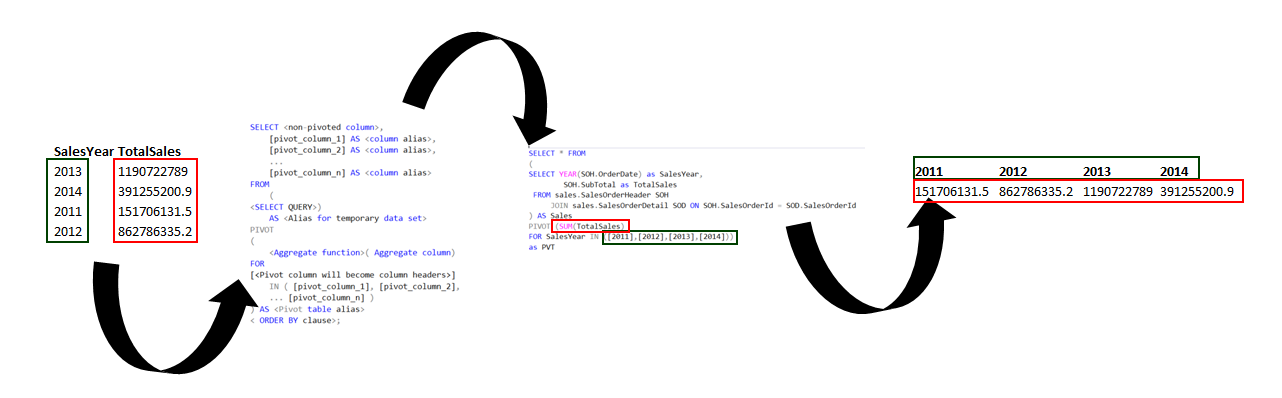
Practical implementation of the PIVOT function in SQL involves techniques such as conditional aggregation and dynamic SQL. These strategies offer analysts a versatile toolkit to tailor data restructuring to meet specific analytical needs finely.
Conditional aggregation within the context of the PIVOT function in SQL allows analysts to apply aggregate functions selectively based on predefined conditions. For instance, when pivoting sales data, to showcase sales figures, conditional aggregation can be employed to calculate different metrics, such as total sales, average sales, or maximum sales, depending on specific criteria like product categories or time periods. This level of flexibility provides a nuanced perspective, allowing analysts to derive more targeted insights from their data.
Dynamic SQL, on the other hand, introduces an element of adaptability to the pivoting process. Unlike static SQL, which requires predefined queries, dynamic SQL and dynamic Pivot allow analysts to construct and execute SQL statements dynamically during runtime. This proves invaluable when dealing with varying datasets or evolving analytical requirements. Analysts can adjust pivot conditions on the fly, making the entire process more responsive and adaptable to changing data landscapes.
By incorporating these advanced techniques, analysts can elevate their proficiency in SQL pivoting, transforming it from a straightforward data rearrangement tool to a dynamic and responsive mechanism for extracting intricate insights from complex pivot operations. This adaptability ensures that analysts can effectively navigate diverse datasets and evolving analytical scenarios, unlocking the full potential of SQL Pivot data for comprehensive and tailored data analysis within their Pivot table.
Moreover, the power of SQL Pivot data extends beyond organizational benefits. The transformed datasets are not only more accessible for analysis but also seamlessly integrated with other Business Intelligence (BI) tools.
Nonetheless, this integration enhances visualization and reporting capabilities, elevating the overall interpretability of data. Consequently, the art of pivoting in SQL is not merely a technical maneuver but a dynamic and indispensable technique that empowers analysts to reshape data, unlock insights, and enhance the impact of analysis outcomes in the ever-evolving landscape of data-driven decision-making for each Pivot operator.
Advanced SQL Functions
Nevertheless, learning how to make the most of the PIVOT function in SQL will not get the job done on its own in order to unlock data-derived insights and make better business decisions. To do that, you should also be aware of the numerous advanced SQL functions you can add to the Pivot syntax in your arsenal, with two leading the way: the aggregation functions for complex analysis and the window functions.
Aggregation Functions for Complex Analysis
First things first, advanced aggregation functions such as SUM, AVG, COUNT, and others serve as indispensable tools for delving into the intricacies of complex datasets. These functions go beyond basic calculations, offering a nuanced approach to data analysis. SUM aggregates total values, AVG calculates averages, and COUNT provides a count of data points, enabling analysts to gain comprehensive insights into dataset characteristics.
Their application is not limited to singular metrics; rather, they contribute to a holistic understanding of data distributions and trends. By leveraging these advanced aggregation functions, analysts can conduct more sophisticated analyses, extracting meaningful patterns and drawing informed conclusions from intricate datasets.
Window Functions and Their Applications
Window functions represent another powerful facet of data analysis, offering a unique perspective on dataset relationships. Unlike traditional aggregation functions that consider the entire dataset, window functions operate within defined partitions or “windows” of the dataset. This enables analysts to perform calculations over specific subsets of data, providing a more granular and context-aware analysis.
Practical applications of window functions are diverse. They prove invaluable in scenarios where a comparative analysis is essential. For instance, window functions make calculating rolling averages over time or determining cumulative sums within specific categories seamless. These functions also facilitate ranking, enabling analysts to identify top-performing entities within each partition.
Utilizing SQL Indexing
Apart from using the SQL Pivot data function, SQL indexing is crucial in enhancing query performance by expediting data retrieval. Acting as a roadmap for the database engine, indexes enable swift access to specific rows, significantly reducing query execution time.
This acceleration is particularly pronounced in large datasets where indexing efficiently narrows down the search space. Indexing ensures that queries run seamlessly by prioritizing the retrieval of relevant data and optimizing overall database performance.
In essence, indexing is a crucial mechanism for streamlining data access and enhancing the efficiency of SQL queries, especially when dealing with extensive datasets.
Optimizing Query Performance
Enhancing the speed and efficiency of SQL queries is pivotal for proficient data analysis. Therefore, various optimization techniques encompass multiple strategies, with indexing at the forefront. Indexing streamlines data retrieval, significantly boosting query speed, especially in large datasets. A well-structured query is equally vital; organizing conditions and joins efficiently ensures optimal execution. Beyond these fundamentals, advanced optimization strategies involve carefully tuning database configurations and caching mechanisms, and leveraging query execution plans.

Introducing tools designed for analyzing and improving SQL query performance adds another layer to optimization. Tools such as SQL Profiler and Query Execution Plans provide insights into query behavior, enabling analysts to pinpoint inefficiencies. Overall, a holistic approach, combining indexing, query structure refinement, and specialized tools, ensures a finely tuned database system, optimizing the speed and efficiency of SQL queries for comprehensive data analysis.
Handling Big Data with SQL
Effectively managing large datasets with SQL presents unique challenges in data analysis. As datasets scale, conventional SQL methods encounter performance bottlenecks. To address this potential issue, you should know that many specialized tools and techniques are tailored for processing big data within SQL environments.
These tools, such as Apache Hadoop and Spark, enhance SQL’s capabilities for large-scale data processing. Moreover, seamless integration with big data platforms ensures SQL’s adaptability. By navigating the complexities of large datasets through purpose-built tools and strategic integration, SQL becomes a powerful ally in big data analytics, facilitating efficient data processing and extracting valuable insights.
Integration with BI Tools
Last but not least, integrating SQL with BI tools is pivotal for unlocking advanced analytical capabilities. This symbiotic relationship enhances the overall data analysis process by seamlessly connecting SQL, the language of databases, with the visualization and reporting power of BI tools.
The importance lies in bridging the gap between raw data stored in databases and the meaningful insights required for decision-making. This integration empowers users to leverage SQL queries directly within BI tools, ensuring a fluid and comprehensive analysis. By doing so, organizations can harness the full potential of SQL for data extraction and manipulation while simultaneously capitalizing on the sophisticated visualization and reporting features offered by BI tools. This collaborative integration streamlines the analytical journey, transforming complex datasets into clear, actionable insights.
Final Words
In exploring SQL’s multifaceted role in data analysis, we’ve uncovered vital concepts and techniques for extracting meaningful insights. Beginning with the fundamentals, we navigated through each and every important aspect of knowing how to utilize SQL, including its most important SQL PIVOT function for data analysis, to learn the language’s transformative power in reshaping data and providing a fresh perspective for your business.
As we conclude, the synergy of these concepts positions SQL not just as a language for managing databases but as a dynamic force empowering analysts to navigate, manipulate data, and extract profound insights from the intricate landscapes of data. Armed with this comprehensive understanding, readers are poised to leverage the full potential of SQL in their data-driven endeavors.
However, if you still feel like you need additional expert help, you can always reach out to ESW and leverage our professional in-house teams for all of your SQL needs. Please do not hesitate to schedule a free consultation or reach out to us at +1-833-957-3062 to get in touch with our professionals, who will come up with a comprehensive plan of how you can make the most out of your data with SQL Pivot and more.